共识算法
根据商业场景中系统可靠性、性能、安全性、是否存在算力消耗等不同要求,趣链区块链平台(以下简称“平台”)采用自适应共识机制,支持RBFT(BFT类)、NoxBFT、Raft以及solo等多种共识算法来满足不同的业务场景需求,每种算法的原理及特点将在下文一一介绍。
RBFT
鉴于公链中的POW共识等算法存在算力消耗浪费资源等问题,传统PBFT算法在可靠性与灵活性方面不够完善,平台改进算法RBFT(Robust Byzantine Fault Tolerant),极大地提高了传统PBFT的可靠性与性能。RBFT能够将交易的延时控制在300 ms,最高可以支持每秒上万笔的交易量,为区块链的商业应用提供了稳定高性能的算法保障。同时,平台通过Recovery机制,解决单点自动恢复、账本动态数据自动恢复等可靠性难题,保证集群非停机的情况下节点动态增删、热备切换和动态数据失效恢复(ARCM),大大增强了共识模块的可用性。
共识流程
RBFT共识算法的核心在于保证了区块链各节点以相同的顺序处理来自客户端的交易。其中,图中的Primary节点为区块链中动态选举出来的主节点,负责对客户端消息的排序打包,Replica节点为备份节点,所有Replica节点与Primary节点执行交易的逻辑相同。
RBFT共识流程如下图所示:
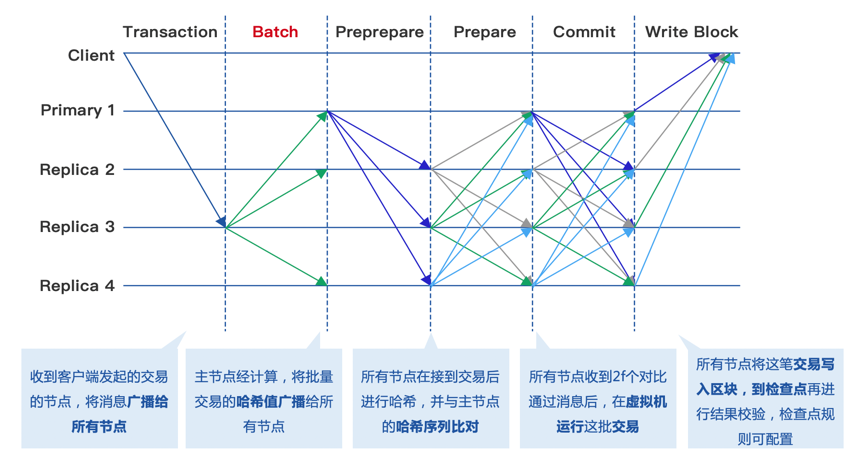
- 客户端Client将交易发送到区块链中的任意节点;
- Replica节点接收到交易之后转发给Primary节点,Primary自身也能直接接收交易消息;
- Primary会将收到的交易进行打包,生成batch进行验证,剔除其中的非法交易;
- (三阶段第一阶段)Primary将验证通过的batch构造PrePrepare消息广播给其他节点,这里只广播批量交易的哈希值;
- (三阶段第二阶段)Replica接收来自Primary的PrePrepare消息之后构造Prepare消息发送给其他Replica节点,表明该节点接收到来自主节点的PrePrepare消息并认可主节点的batch排序;
- (三阶段第三阶段)Replica接收到2f个节点的Prepare消息之后对batch的消息进行合法性验证,验证通过之后向其他节点广播Commit消息,表示自己同意了Primary节点的验证结果;
- Replica节点接收到2f+1个Commit之后执行batch中的交易并同主节点的执行结果进行验证,验证通过将会写入本地账本,并通过checkpoint检查点来进行结果校验的步骤,检查点规则可配置。
由以上的RBFT常规流程可以看出,RBFT将交易的验证流程穿插于共识算法的整个流程中,做到了对写入区块结果的共识。首先,Primary节点接收到交易之后首先进行验证,这保证了平台的算力不会被非法交易所消耗,使Replica节点能够高效地处理Primary节点的拜占庭失效。其次,Replica节点在接收到2f个Prepare消息之后对Primary节点的验证结果进行验证,如果结果验证不通过则会触发ViewChange消息,这再一次保证了系统的安全性。
视图更换
Viewchange(视图更换)是指因原Primary节点失效而Replica节点参与新Primary节点选举的过程,该机制是保证整个共识算法健壮性的关键。
Viewchange流程如下图所示:
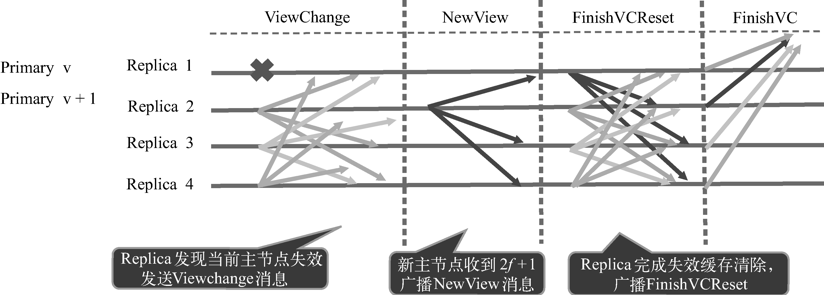
- Replica节点检测到主节点有以上异常情况或者接收来自其他f+1个节点的ViewChange消息之后会向全网广播ViewChange消息;
- 当新主节点收到N-f个ViewChange消息时,会发送NewView消息;
- Replica节点接收到NewView消息之后进行消息的验证和对比,验证View的切换信息相同之后正式更换ViewChange并打印FinishVC消息,从而完成整个ViewChange流程。
节点增删
在联盟链的场景下,由于联盟的扩展或者某些成员的退出,需要联盟链支持成员的动态进出服务,而传统的PBFT算法不支持节点的动态增删。RBFT为了能够更加方便地控制联盟成员的准入和准出,为PBFT添加了保持集群非停机的情况下动态增删节点的功能。RBFT新增节点流程如下图所示:
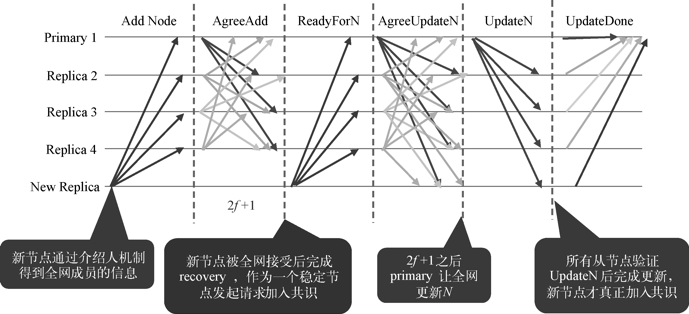
- 首先,新的节点需要得到证书颁发机构颁发的证书,然后向联盟中的所有节点发送请求;
- 各个节点确认同意后会向联盟中的其他节点进行全网广播,当一个节点得到2f+1个同意加入的回复后会与新的节点建立连接;
- 随后,当新的节点和N-f(N为区块链联盟节点总数)个节点建立连接后就可以执行主动恢复算法,同步区块链联盟成员的最新状态;
- 随后,新节点再向主节点请求加入常规共识流程。最后,主节点确认过新节点的请求后会定义在哪个块号后需要改变节点总数N来共识(确保新节点的加入不会影响原有的共识,因为新节点的加入会导致全网共识N的改变,意味着f值可能改变)。
RBFT动态删除节点流程和新增节点流程类似。
数据恢复
区块链网络在运行过程中由于网络抖动、突然断电、磁盘故障等原因,可能会导致部分节点的执行速度落后于大多数节点或者直接宕机。在这种场景下,节点需要能够做到自动恢复并将账本同步到当前区块链的最新账本状态,才能参与后续的交易执行。为了解决这类数据恢复工作,RBFT算法提供了一种动态数据自动恢复机制。
RBFT的自动恢复机制通过主动索取区块信息,使自身节点的存储状态尽快和整个系统最新的存储状态一致,增强了区块链系统的可用性。
NoxBFT
联盟链的共识机制大多选择确定的共识算法,如RAFT,PBFT等,这些共识算法不存在分叉问题,因此在节点总数不多、网络规模不大的时候可提供较高的产块效率。但随着节点数量增多到几十甚至上百个共识节点的规模,所需要交换的信息量也呈指数级增长,最终导致系统负载增加及网络通信量增大,性能下降会很明显,因此其可扩展性不强。
为了更好的适应大规模应用场景,平台基于HotStuff算法,实现了一种可扩展、高性能的新型的共识算法---NoxBFT。NoxBFT算法在保留原有RBFT算法高效性与鲁棒性的前提下,从三个方面实现了支持以千为数量级的大规模节点组网共识。首先,NoxBFT通过星型网络拓扑结构将网络复杂度将降低至n;其次,NoxBFT通过聚合签名实现了签名的快速验证,同时还支持动态扩展。
建议参照术语部分的名称解释阅读下文内容。
共识流程
NoxBFT算法的共识流程主要是Proposal提案阶段与Vote投票阶段的循环,具体流程如下图所示:
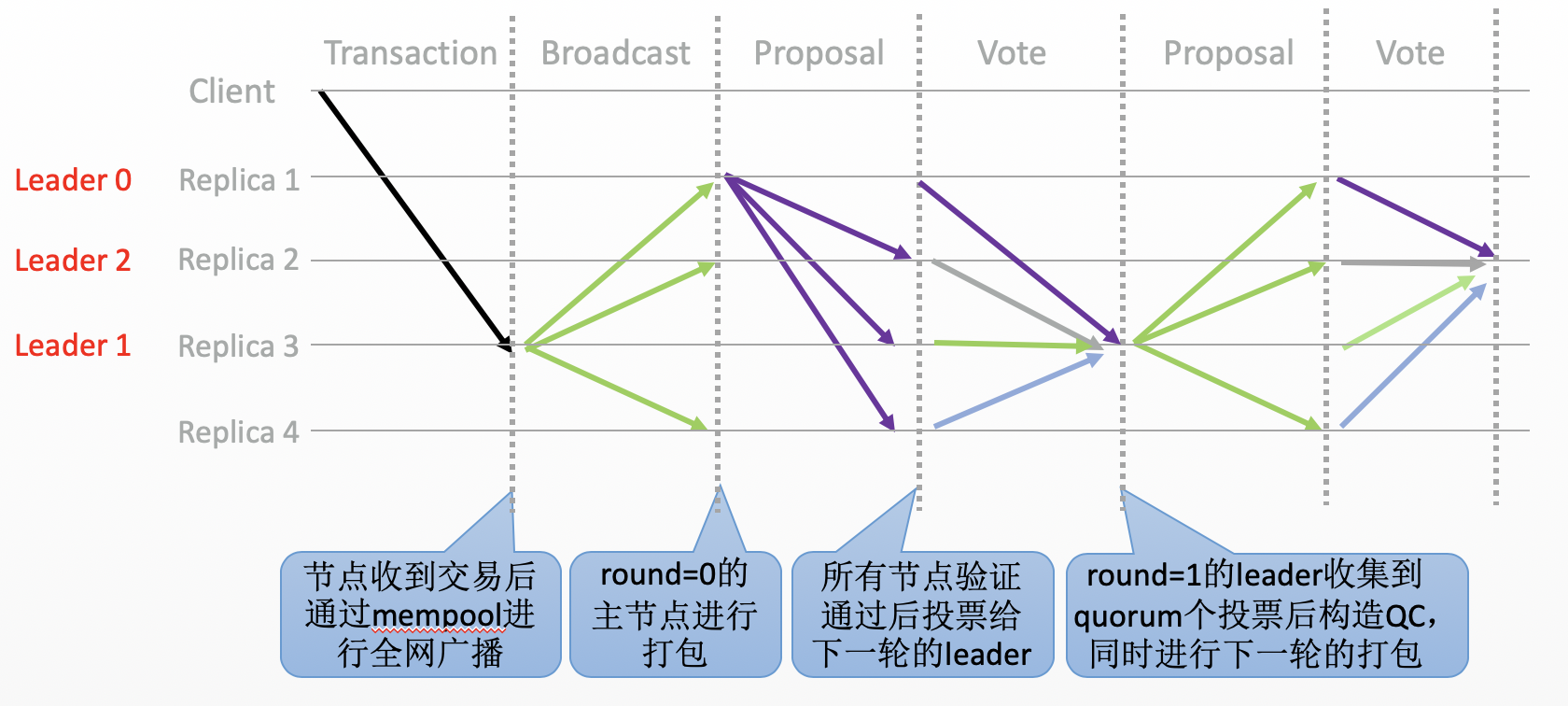
- Transaction&Broadcast:任意节点收到交易之后,首先将其存入到本地mempool中,随后将其广播给其他所有节点,收到广播的节点也会将其存入到各自的mempool中。每个节点在接收到交易后,都会进行交易的去重判断,剔除重复交易之后才能进入到节点的mempool中;
- Proposal:当前轮次的主节点负责进行打包,从mempool中取出若干笔符合要求的交易打包成一个batch,并附带上一轮的QC封装成一个proposal,广播给其他节点;
- Vote:所有的节点在监听到提案消息后,都会验证proposal的合法性(safety rules),验证通过后,首先检查该proposal中的QC证书(QuorumCert)是否达到了3-chain安全性提交规则(commit rules),达到后则直接提交区块,等待区块执行完成之后将其中的交易从mempool中移除(CommitTxs)。最后,节点会将投票(vote)信息发送至下一轮的主节点。需要注意的是,每个节点的投票中都会附带上节点签名; Proposal:下一轮的主节点收到quorum个vote后,聚合成一个QC,并开始下一轮打包,并重复步骤2与步骤3,一直到出现超时的情况。
超时轮换
当主节点由于网络原因或者其他因素导致从节点无法按期收到Proposal进行投票时,NoxBFT就会触发超时机制,通过Pacemaker活性模块让全网快速地进入到下一个round继续共识。
超时轮换主节点的流程如下图所示:

- Transaction&Broadcast&Proposal:所有共识节点接收交易并且广播交易,当前的主节点正常的进行打包并广播proposal;
- Round Timeout:由于网络原因,导致主节点proposal并没有及时地发送到从节点,因此从节点不会对本轮次进行投票;
- Broadcast TimeoutMsg:所有节点都无法按期收到本轮的Proposal,导致超时,全网广播TimeoutVote消息,其中会附带上本节点当前所处的轮次号以及节点的签名;
- Proposal:下一轮的主节点在一定时间内收到 quorum个TimeoutVote消息,构造成TC(Timeout cert),并从mempool中取出若干笔合法交易打包成batch,即可将TC与batch封装成一个新的提案proposal进行广播。
RAFT
与BFT类共识算法相比,CFT共识,尤其是Raft共识算法,从性能、可理解性和可实现性等方面来说具有一定优势。与不限制共识成员的公链不同,联盟链中所有参与节点的身份都是已知的,每个节点有很高的可信度,故在某些可信度高的业务场景下可采用不容拜占庭节点的传统共识算法,基于此,平台同时支持Raft共识算法。
角色介绍
首先在Raft共识机制中,节点共分为三种角色:
- 领导者(Leader):接受客户端请求,并向从节点同步请求日志,当日志同步到大多数节点上后将提交日志,并广播给从节点。
- 从节点(Follower):单向接收并持久化主节点同步的日志。
- 候选节点(Candidate):主节点选举过程中的过渡角色,当从节点在规定的超时时间内没有收到主节点的任何消息,将转变为候选节点,并广播选举消息,且只有候选状态的节点才会接收选举投票的消息。候选节点有可能被选举为主节点,也有可能回退为从节点。
在同一时刻,集群中只有一个Leader,负责生成日志数据(对应在区块链中即负责打包)并广播给Follower节点,为了保证共识的正确性和简单性,所有Follower节点只能单向接收从Leader发来的日志数据。
共识流程
Raft算法共识流程分为主节点选举和日志同步两步。将时间分为一个个的任期(term),每一个term以Leader选举开始。在成功选举Leader之后,Leader会在整个term内管理整个集群。如果Leader选举失败,该term就会因为没有Leader而结束。
具体共识流程如下图所示:
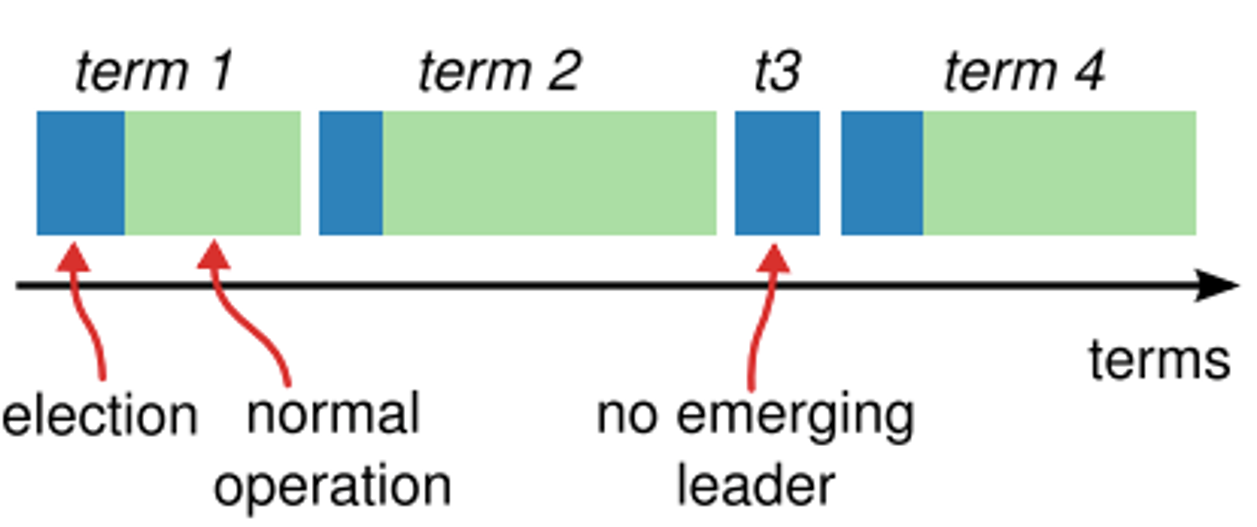
- 领导人选举:Raft 使用心跳(heartbeat)触发Leader选举。当服务器启动时,Leader向所有Followers周期性发送heartbeat。如果Follower在选举超时时间内没有收到Leader的heartbeat,就会发起一次Leader选举。Follower将其当前term加一然后转换为Candidate。它首先给自己投票并且给集群中的其他服务器发送RequestVoteRPC。当赢得了多数的选票,成功当选为Leader后,它会重复开头的操作,即定期向所有Followers发送heartbeat维持其统治;
- 日志同步:Leader选出后,就开始接收客户端的请求。Leader把请求作为日志条目(Log entries)加入到它的日志中,然后并行的向其他Follower节点发起AppendEntries RPC以复制该日志条目。当这条日志被复制到大多数服务器上,Leader将这条日志应用到它的状态机并向客户端返回执行结果。
SOLO
为了简化共识的配置信息及工作流程,降低平台的试用门槛,平台提供了单节点SOLO共识算法。基于solo共识算法的单机版节点屏蔽了网络延迟等不可控因素,这使得开发人员可以专注于自己模块本身的开发和调试。
开放下载版本便是采用SOLO算法。