账本存储
区块链本质上是一个分布式账本系统,因此区块链平台的账本设计至关重要。
趣链区块链平台(以下简称“平台”)的账本数据主要包含2个部分:
- 区块数据:交易信息通过区块链这种链式结构进行存储,保证了用户交易的不可篡改以及可追溯性
- 状态数据:采用账户模型维护区块链系统的状态,即图中state data部分
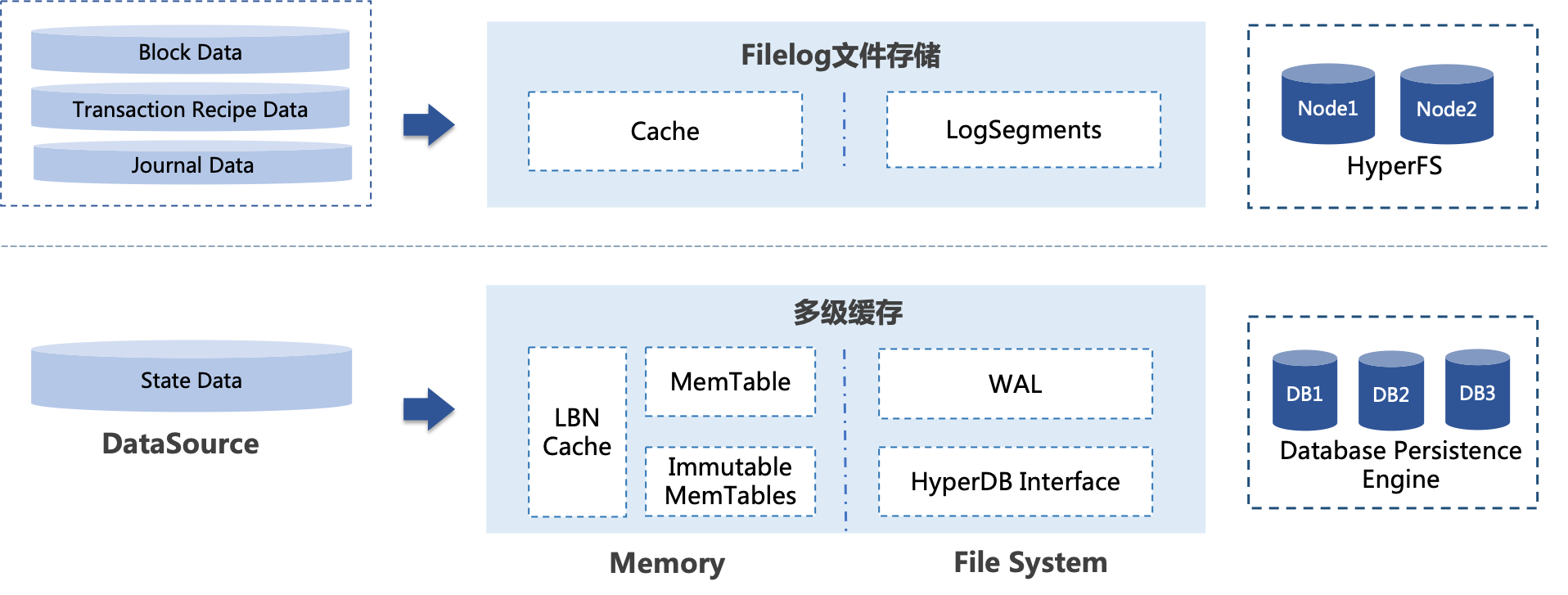
数据结构
区块链
区块链是区块链账本中的重要数据结构,存储着核心交易信息。区块链是由包含交易信息的区块从后向前有序链接起来的数据结构。所有区块被从后向前有序地链接在这个链条里,每一个区块都指向其父区块。区块链经常被视为一个垂直的栈,第一个区块作为栈底的首区块,随后每个区块都被放置在其他区块之上。用栈形象化地表示区块依次链接这一概念后,我们便可以使用一些术语,例如,“高度”表示最新区块与首区块之间的距离,“顶部”或“顶端”表示最新添加的区块。
合约状态
与比特币系统采用UTXO模型不同,平台采用了账户模型来表示系统状态。当节点收到一笔“待执行”的交易后,会首先交由执行模块执行。执行交易结束后,会更改相关合约账户的状态,例如某用户A发起一笔交易调用已部署的合约B,使得合约B中的变量值b由0变为1,并持久化到合约状态中存储。每一笔交易的执行,即意味着合约账户状态的一次转移,也代表着系统账本的一次状态转移。因此,趣链区块链平台也可以被认为是一个状态转移系统。
存储机制
在区块链中,对于区块数据的和状态数据的数据类型和特点是全然不同的。区块数据主要通过区块的形式进行串联,所有区块被从后向前有序地链接在一个链条里,每一个区块都指向其父区块;状态数据,其实是一系列的KV键值对,每次执行一笔交易,修改一系列状态变量,从底层来看,就是更新了一批KV对。区块数据的特征是不断追加不断增长,而状态数据往往是频繁更新不会持续增长。
为了解决存储的IO瓶颈,平台自主研发混合存储引擎机制,对于区块数据采用区块链专用存储引擎Filelog,对于KV型状态数据选用具备很高随机写顺序读性能的存储引擎LevelDB,以此实现区块数据与状态数据的分离,保证在系统数据量不断增大的情况下读写性能不受影响。此外,针对状态数据,平台还设计了多级缓存机制,从而实现状态数据高效存储。
Filelog
Filelog是趣链自主研发的顺序性数据存储引擎,用来存储区块链场景中的区块数据、回执数据等等一类按照区块号严格递增的数据,因此filelog的基本操作仅包括read/write两种。
平台底层数据库有三个filelog数据库,blockFilelog、journal、receiptFilelog。其中blockFilelog用于存储区块数据,journal用于保存journal,receiptFilelog用于存储回执。这三类数据在filelog中的key均为对应的区块号。
Filelog的特点:
- 顺序写:每一条数据均与一个唯一的sequence number相绑定,且sequence number单调递增
- 随机读:读取时每一个sequence number都有可能会被随机读到,不按照递增顺序
- 数据可迁移:平台支持数据归档,即将历史数据从线上迁移到线下路径中
- 对于连续型的块链数据, Filelog的读写性能都优于LevelDB,特别是数据的写入性能有了大幅提升
levelDB
LevelDB是Google开源的持久化KV单机数据库,具有很高的随机写,顺序读/写性能,但是随机读的性能很一般,适合应用在查询较少,而写很多的场景。
目前平台中有四个levelDB数据库,其中consensusDB用于保存共识状态,mqDB和radarDB分别用于存储mq和radar服务执行过程中产生的一些信息,而certDB用于保存证书。
LevelDB的特点:
- 随机读写:key是无序的,交易执行过程中任何已有的或还不存在的数据都有可能会被访问到
- key和value都是任意长度的字节数组
- 可以创建数据的全景snapshot(快照),允许在快照中查数据
- 支持批量操作以原子操作进行
Multicache
multicache是一个集读写缓存与底层数据库于一体的组件,提供统一的批量写入服务,可直接对接分布式LevelDB数据库.
multicache有如下特点:
- 在分配的内存空间范围内,multicache将写数据库的操作转化为写内存,实现效率提升
- 在时间局部性强的应用中,multicache用于缓存写数据的内存空间可以很好的对读操作提供服务,提升读效率
- 数据可回滚:一旦出现异常区块,平台的回滚机制要求这些数据库中的内容按区块号进行回滚